











































![CCTV-17农业农村 | [中国三农报道]中国科学院植被病虫害遥感监测与预测系统升级版发布](/uploads/202208/630c32e37f65b.png)





































近年来,全国多个省份地区已经开始着手建设属于自己的遥感样本库,这一良好的趋势表明了各方政府正在积极响应并落实关于推广“人工智能”这一新兴技术的科技政策,也肯定了国家对于发展AI技术与各行各业深度融合的决心和愿景。
利用深度学习技术进行遥感图像智能解译已成为当前自然资源部在面临国土问题作出精准快速决策的重要手段。深度学习技术当前主要依赖“监督学习”分类方式,即必须有海量样本数据参与训练,最终的模型也就是从这些样本蕴含的信息中进行的抽象结果。因此,如何构建一套完整、稳定、合理的样本库体系成为模型训练前期最重要的任务和难题。
由于遥感数据的复杂性及遥感业务成果需求的多样性,遥感样本库的建成往往需要综合考虑多方面因素,究其本质也就是致力于平衡“AI算法、遥感影像特性、业务规则、标注成本及效率”几者之间的冲突。因此,这对于建设者提出了较高的要求,需要其对AI基本原理、遥感专业知识、项目管理能力等要有一个基本的掌握。我们一直倡导“授人以渔”的理念,从解决实际问题的角度出发,尽管全国不同的地区对于遥感解译业务关注的重点有所区别,实施方案也都别具一格,但是“万变不离其宗”,绝大多数AI算法对于训练样本的质量追求都是一致的,只要掌握样本库建设的底层逻辑,在面对各种复杂的业务场景时,也能够形成一套适用于自身业务的独特且合理的建设方案。下面根据作者自身的理解和经验列举出样本库建设的几个关键环节:
明确分类体系
明确分类体系是样本库建设工作的基础,其主要目的是标准化 “人”的认知思维。
制定标准规则
制定出既适合AI算法原理又适合业务需求的标注规则,其主要目的是标准化“人”的作业成果质量,让“计算机”清晰地知道我们需要的是什么。
样本选择
在有限的样本数量之内,如果有对特征分析处理的意识有助于提高模型的泛化能力。
样本库管理
制定出一套能容纳所有遥感业务类型的样本库管理系统或方案,其主要目的是有序积存海量遥感数据,便于未来发挥潜在价值。
01.
明确分类体系 CLASSIFICATION SYSTEM
“分类体系”的概念官方定义比较抽象,如果思维深度不够,很难对它有一个全面的认知。简单来说,“分类体系”可以理解为是针对于体系下的所有个体,按照某种特定的规律(如根据视觉、触觉、听觉等感官能力...)发现其可区分、可信的特征差异,从而进行分类。不同的分类体系对于同一个体可能会有不同的定义。 为什么说AI和遥感图像具有天然的耦合性?因为不管是AI视觉算法还是传统遥感图像解译,都是通过视觉能力的特性寻找要素的特征差异来实现分类。分类体系内的类别越多、区分度越低,对应样本数量就需要越多、模型训练难度就会越大,所以如何编制出一套简洁自洽、贴合业务的分类体系,是样本库建设中最重要的工作之一。而建设者需要“拉齐认知”,也就是需要将自身知识经验的无序状态变为经过分类的有序状态,以完成标准统一的认知过程。
遥感业务场景多样,不同的业务场景对于最终的成果需求也会有所不同,建设者需对业务规则充分了解,使之与AI算法有机结合,从而明确出适合业务的分类体系。遥感行业常见的分类体系有地理国情普查分类体系和三次国土调查分类体系,作为两项重大的国情国力调查,目的都是为了查清我国自然资源家底,并且年度地理国情监测调查和年度国土变更调查分别是这两项重大调查工作的年度信息更新手段,确保我国的自然资源数据的实时性。这两项调查工作都对土地利用情况进行了分类,但是两者在侧重点上各有不同:
地理国情普查侧重于反映土地的植被覆盖及使用情况,从土地本身的自然特征着手,其分类偏向于自然属性;
第三次国土调查(土地利用现状)侧重于从管理的属性出发,目的是真实的反映土地的利用状况及潜力,其分类偏向于社会经济属性。
两种分类体系的异同分析可参考【地理国情普查与三调数据的共享探析】
当然,有的业务规则可能会将两种分类体系结合使用,或者在此基础上延伸出其它变种分类体系。究其根本,不管使用何种分类体系,都须要满足这样几点原则:
Ⅰ.所有类别能通过目视区分,不掺杂人为主观判断力和经验;
Ⅱ.分类体系应自洽、客观,避免“同物异类”情形;
Ⅲ.分类体系应涵盖所有业务关注的地类,凡能精简、归并的地类尽量归并;
Ⅳ.分类体系一旦确定,尽可能不改、小改。
02.
制定标注规则 STANDARD RULES
没有明确分类体系的业务规则都是“耍流氓”,分类体系是业务规则的根基。明确分类体系后,我们再来谈谈业务规则。不同的遥感业务对于其规则的制定也有所不同,比如土地卫片执法、国土变更调查、重要生态空间人类活动变化监测、城市违建监测等。大多数情况下,最终制定出的标注规则=AI原则+业务规则(+特殊场景说明),即站在AI算法的角度先约束几条原则,再按照业务规则的作业要求去标注,有些复杂的业务场景下还需要补充一些特殊说明,防止逻辑混乱。要遵循的AI原则主要有如下几点:
Ⅰ.所见即所得
标注员仅通过目视影像标注,不参考影像之外的其他数据(如三调数据库),不掺杂人为主观的经验和知识标注。
Ⅱ.统一可区分
标注员之间应形成对规则统一的理解和认知,避免相互冲突;标注员自身时刻也要统一一套作业准则,避免自相矛盾。
Ⅲ.标签完整性
用作训练的影像,尽量避免 “漏标注”和“错标注”,以免降低模型效果。
Ⅳ.变化可逆性
所有变化图斑可逆,不区分前后影像类别先后顺序,如“建筑变耕地”和“耕地变建筑”可理解为是同一类变化。
03.
样本选择 SAMPLE SELECTION
样本的选择一定程度上关乎着样本标注的成本和最终模型的效果,按照一个正确的思路去进行样本的选择,是整个样本库建设工作的基础保障。关于样本的选择,如不考虑影像获取的难度和矢量采集成本,在适合标注规则的前提下本着“越多越好”的原则;如果考虑成本,关于样本的选择可遵循以下原则:
Ⅰ.充分分析业务场景范围内的影像各维度特征,优先选择强代表性的样本;
(影像维度包括:传感器、时空分辨率、地区、地形地貌等等,强代表性指的是最贴合实际业务场景各维度的影像)
Ⅱ.综合考虑分类体系下的类内多样性、类间差异性问题,更多选择分类难度大的样本。
①类内多样性:类内多样性越多,训练难度越高;反之越低。比如耕地,受不同季节、分辨率、地区、成像条件等因素影响,会出现多种特征形态;而像一些形态单一的特定类别比如篮球场、风车等,故训练难度低。
②类间差异性:类间差异性越大,训练难度越低;反之越高。比如耕园林草之间差异性较小,建筑和道路差异性较大,矿石开采与尾矿堆放地差异性较小等等;对于差异性较小的地类间,首先确定人类能够目视可区分,其次可以额外增加此类样本。
Ⅲ.适当选择制作在实际业务场景中对模型检出干扰性较强的负样本,如阴影、季节性差异、自然气象、人类临时性活动.......
当然了,当你的样本量足够多足够大,以上这些类似于“特征工程”的工作其重要性占比就越小,这也是深度学习的优势之一。所以更多时候,样本数量的优先级往往要高于样本质量,当样本数量多出一个量级时,是能够远远弥补在样本质量上落后的那几个点。
04.
样本库管理 SAMPLE LIBRARY
以上三个环节是针对某一个具体的遥感业务或项目所阐述的样本标注思路,样本标注的最终目的也就是训练出一个适合业务生产的高精度AI模型。而随着业务的逐渐增多,样本库的管理也成了一项绕不开的难题。样本库管理是一个长期的工作,需要有顾全局的意识,其主要目的是让所有多样化的样本能够有条不紊的分类入库,并且形成规范,以容纳未来更多的样本,便于在后续调用的时候,能够满足快速、方便、灵活等特点。样本库管理方式可以依托于智能化的平台、系统,也可以采用最朴素的文件夹存储管理方式,不管哪种方式,其管理的底层逻辑一般都按以下三个层级去划分:
层级1——按样本类型
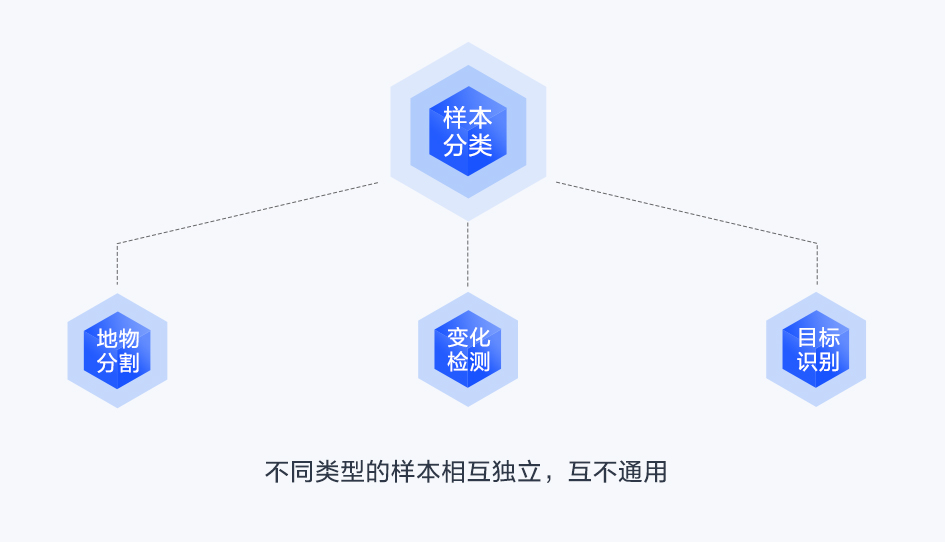
层级2——按分类体系/业务

层级3——按影像属性

除此之外,样本库建设工作还包括数据预处理、标注团队组建、质量控制、样本规格统一等等,这些内容也都不可或缺,但对于经历过测绘遥感相关项目的人员来说这些都不算难题。将以上所有内容串联起来,再结合建设者自身对行业的理解,就可以构建出一套完整的样本库方案了。
注:此篇文章内容均为作者主观阐述总结,请各位读者批判性吸收,欢迎一起交流学习!
